How Far Can a 1-Pixel Camera Go?
Solving Vision Tasks using Photoreceptors and Computationally Designed Morphology

Abstract
A de facto standard in solving computer vision problems is to use a common high-resolution camera and choose its placement on an agent
(i.e., position and orientation) based on human intuition. On the other hand, extremely simple and well-designed visual sensors found throughout
nature allow many organisms to perform diverse, complex behaviors. In this work, motivated by these examples, we raise the following questions:
We explore simple sensors with resolutions as low as one-by-one pixel, representing a single photoreceptor First, we demonstrate that just a
few photoreceptors can be enough to solve many tasks, such as visual navigation and continuous control, reasonably well, with performance comparable
to that of a high-resolution camera. Second, we show that the design of these simple visual sensors plays a crucial role in their ability to provide
useful information and successfully solve these tasks. To find a well-performing design, we present a computational design optimization algorithm and
evaluate its effectiveness across different tasks and domains, showing promising results. Finally, we perform a human survey to evaluate the
effectiveness of intuitive designs devised manually by humans, showing that the computationally found design is among the best designs in most cases.
Overview
Inspiration from Nature
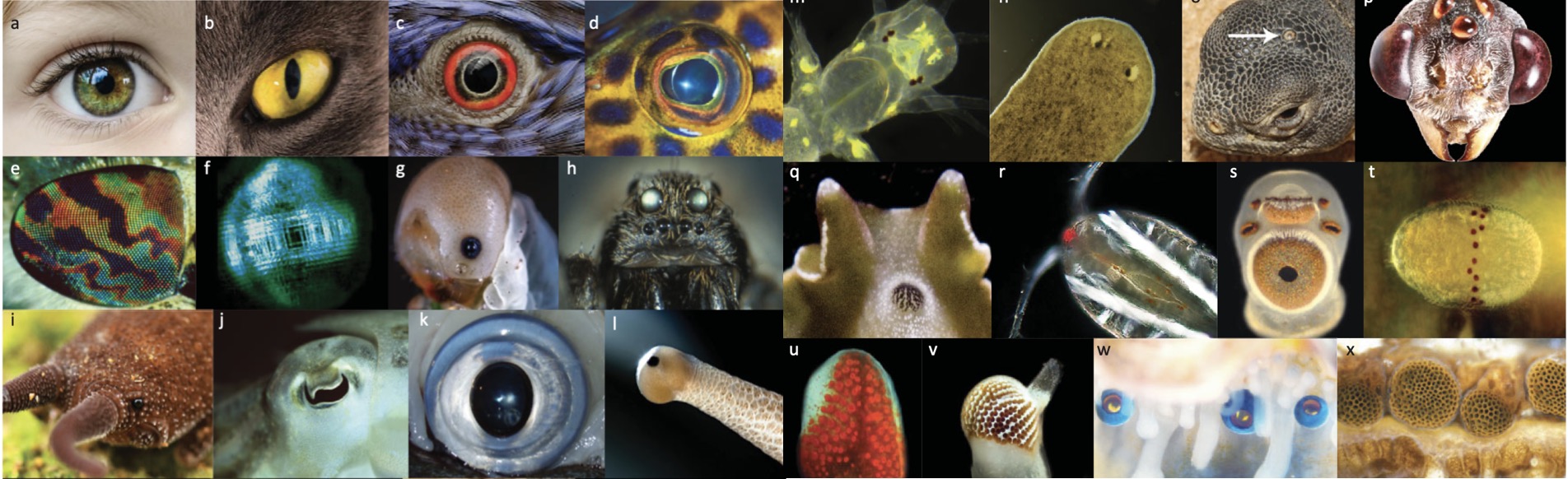
In nature, visual sensors are represented by a wide spectrum of different eyes, including different types of lens structure, pupil shape, resolution, size, placement and more. Source: Nilsson 2021.
1. How far can a simple eye go?
Some animals have extrimely simple eyes (compared to, e.g., human eyes). See, for example, the qualitative comparison of different animals' eyes resolution on the right. Despite the extrimely low-resolution visual signal from their eyes, rats, flies and even mosquitos exhibit rather complex behaviors. Inspired by these examples, we explore how effective can simple visual sensors can be in solving computer vision tasks. Specifically, we replace a standard high-resolution camera with a few extremely simple photoreceptor sensors with resolution as low as 1x1 (one can also think of it as a camera with resolution 1x1).
In the figure below, we show how the performance of a navigating agent depends on the resolution of its visual sensor. We find that even with an extremely low-resolution sensor, the agent can solve the task reasonably well.

Comparable eye resolution of different animals. Source: Prof. Eleanor Caves
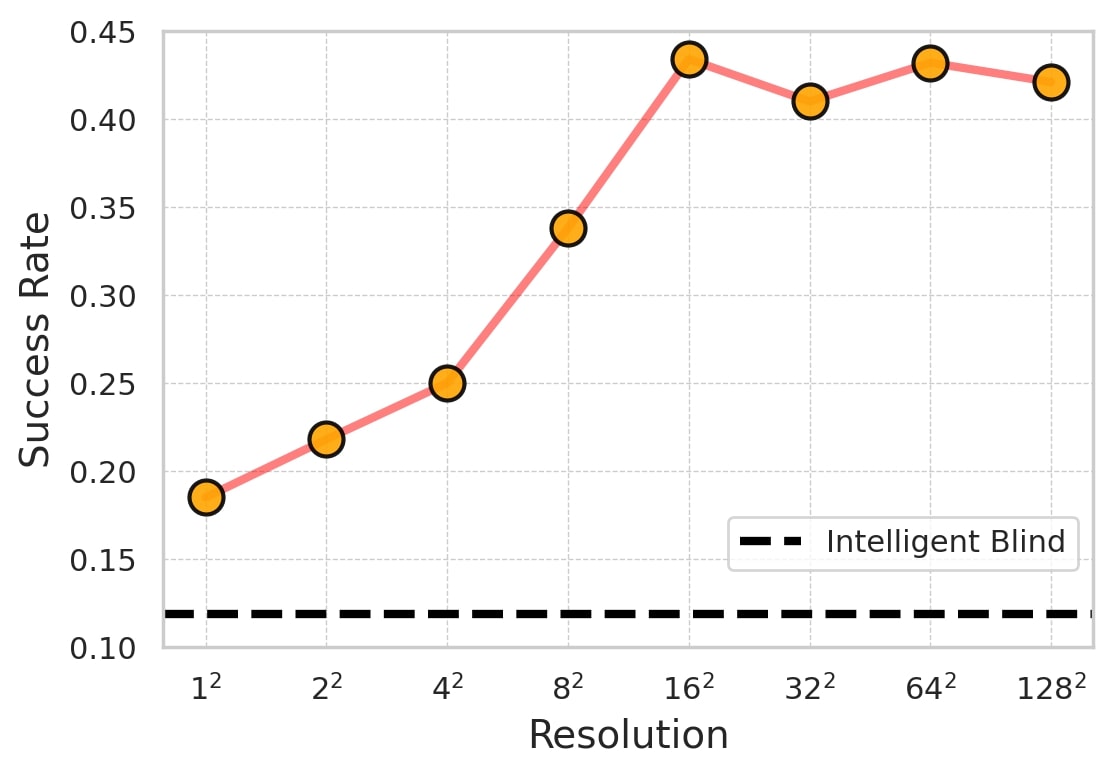
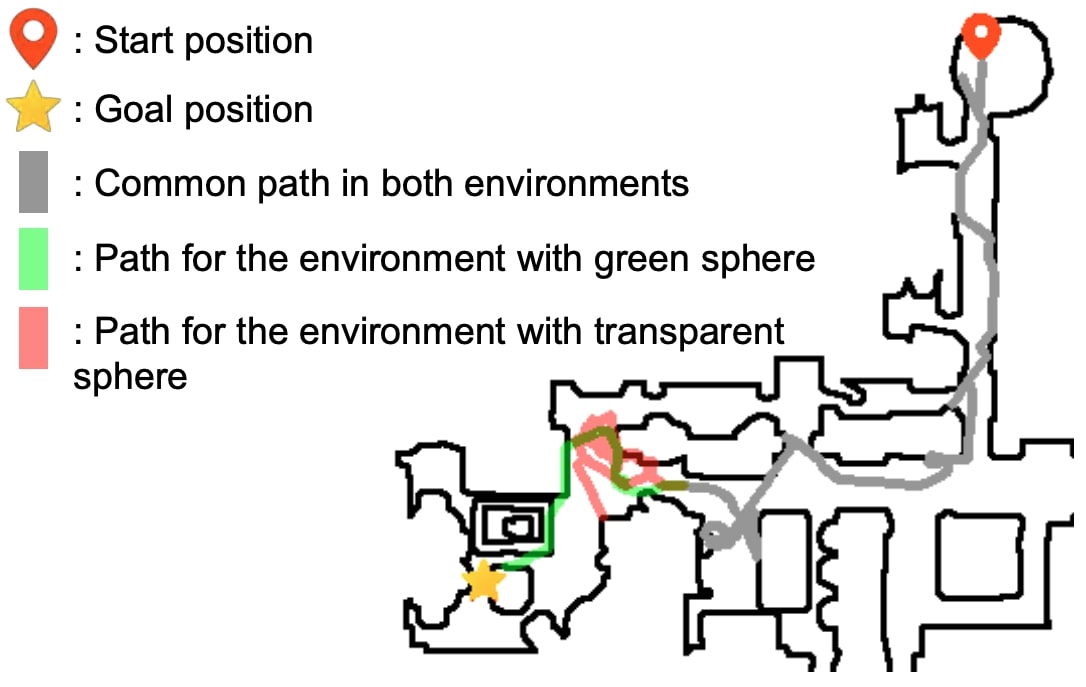
Navigation performance against the sensor resolution. Agents with low resolution sensors can achive good performance, and the performance saturates at a resolution of 16x16 -- far less than the resolution of ordinary cameras (e.g., 8100 times less than a common 1080p camera). (See below for the TargetNav task definition)
A noteworthy point about biological agents is that they are almost never unimodal. They solve their problems using multiple modalities. Utilizing multimodality, e.g. see here, is an interesting direction parallel to the discussion in this project.
2. What role does the design play in the effectiveness of simple eyes?

Anableps anableps : the four-eyed fish. Anatomically they only have two eyes, but each eye is divided by a thin band of tissue into dorsal (upper) and ventral (lower) sections, each with its own cornea and pupil to capture light from above and below the surface helping it hunt both terrestrial and aquatic prey (Perez et al.) Image Source: California Academy of Sciences
This rich variety of animals eyes' designs (its position and orientation in the context of this work) is believed to emerge as evolutionary adaptations to an animal's specific morphology and the ecology in which it lives and to be important to its effectiveness (see The Ecological Approach to Visual Perception by J.J. Gibson). Strategic placement of even the simplest sensors can enable complex behaviors such as obstacle avoidance, detection of coarse landmarks, and even some forms of predator avoidance. For example, in dragonflies, an acute zone facing upward is hypothesized to allow more efficient prey detection by positioning it against the sky instead of a cluttered foliage background (see video by Real Science). Similarly, some species of surface-feeding fish have eyes with horizontal acute zones that allow them to see prey both above and below the water even while entirely submerged by taking advantage of the refractive index of water through their positioning. For a more unusual example, see Anableps anableps, the four-eyed fish on the left (see video by California Academy of Sciences).
Photoreceptors are Effective Visual Sensors
To evaluate the effectiveness of simple photoreceptor sensors, we study agents with (well-designed) PR sensors on navigation (AI Habitat) and dynamic control (DeepMind Control) tasks. We compare the performance of these agents to that of a camera-equipped agent and a blind agent without access to any visual signals.
As seen in the figure on the right, we find that even a handful of well-placed photoreceptors can provide sufficient information to solve some vision tasks with reasonably good performance - significantly higher than a blind agent (scaled to 0) and similar to a more complex camera sensor (scaled to 1).
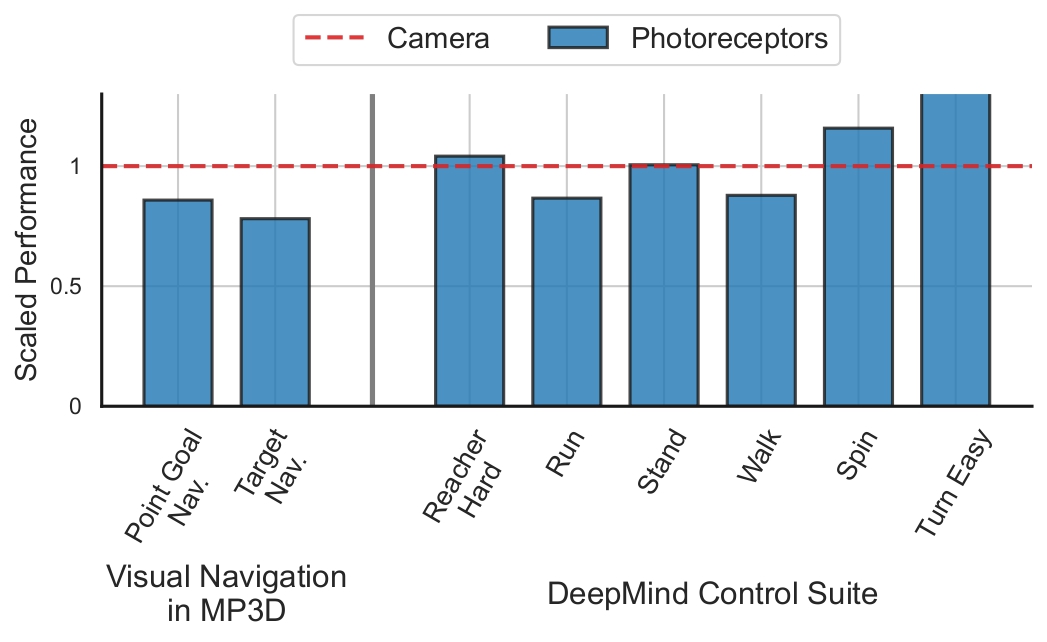
Extremely simple photoreceptor sensors can solve vision tasks reasonably well, comparable to a high-resolution camera.
Visual Navigation in AI Habitat
We consider two navigation tasks in the AI Habitat simulator using scans of real-world scenes from the MatterPort3D dataset. In PointGoalNav, an agent has to navigate to a given target coordinate in a scene. In TargetNav, the agent does not have access to the target coordinate and has to find and navigate to the target sphere which can only be identified visually. As per standard practice, in addition to the visual signal, the agent has access to the GPS+Compass sensor providing its position and orientation w.r.t. its start position.
We study two baselines in comparison to photoreceptor-based agents, an intelligent blind agent and a camera agent. The intelligent blind agent only has access to GPS+Compass sensor while the camera agent has access to visual input of resolution 128 x 128.
Target navigation by a PR based agent.
Photoreceptors enable collision avoidance and finding efficient trajectories
PR agents have few obstacle collisions (comparable to a camera agent) and significantly better than an intelligent blind agent. In the video below, it can be seen that with a blind agent encounters a lot of collision (red dots), heavily relies of wall-following and has low efficiency , i.e. obtains a low SPL. The PR agent similar to the camera agent does better long term path planning, avoids obstacles and has high efficiency, i.e. achieves a high SPL.
Photoreceptors enable efficient scene exploration
PR agents efficiently explore the scene and finds the target in TargetNav. The location of the target sphere is random and unknown in the TargetNav task, therefore, an agent must explore the scene in order to find it.
For each agent, we plot 50 trajectories from two episodes of unseen test scenes. The PR agent explores the scene as efficiently as the camera agent and achieves comparable performance.
Quantitative results
We evaluate the performance of agents on navigation tasks (PointGoalNav and TargetNav) in the AI Habitat Simulator, where we compare the performance of the PR-based agent to the performance of a camera-based agent (both egocentric) and an intelligent blind agent.
Even a simple visual sensor consisting of 32 PRs (two grids of 4x4 sensors) provides useful information, allowing the corresponding agent to outperform significantly an intelligent blind agent without a visual signal.
The PR agents match the performance of the camera agent using the same shallow 3-layer Transformer encoder as for PRs, while having the visual signal bandwidth of only ≈ 1% of that of the 128x128 camera sensor. When compared to the camera agent using the ResNet-50 encoder, a default choice in the literature (“gold standard”) for a fair comparison, PR agents still perform reasonably well.
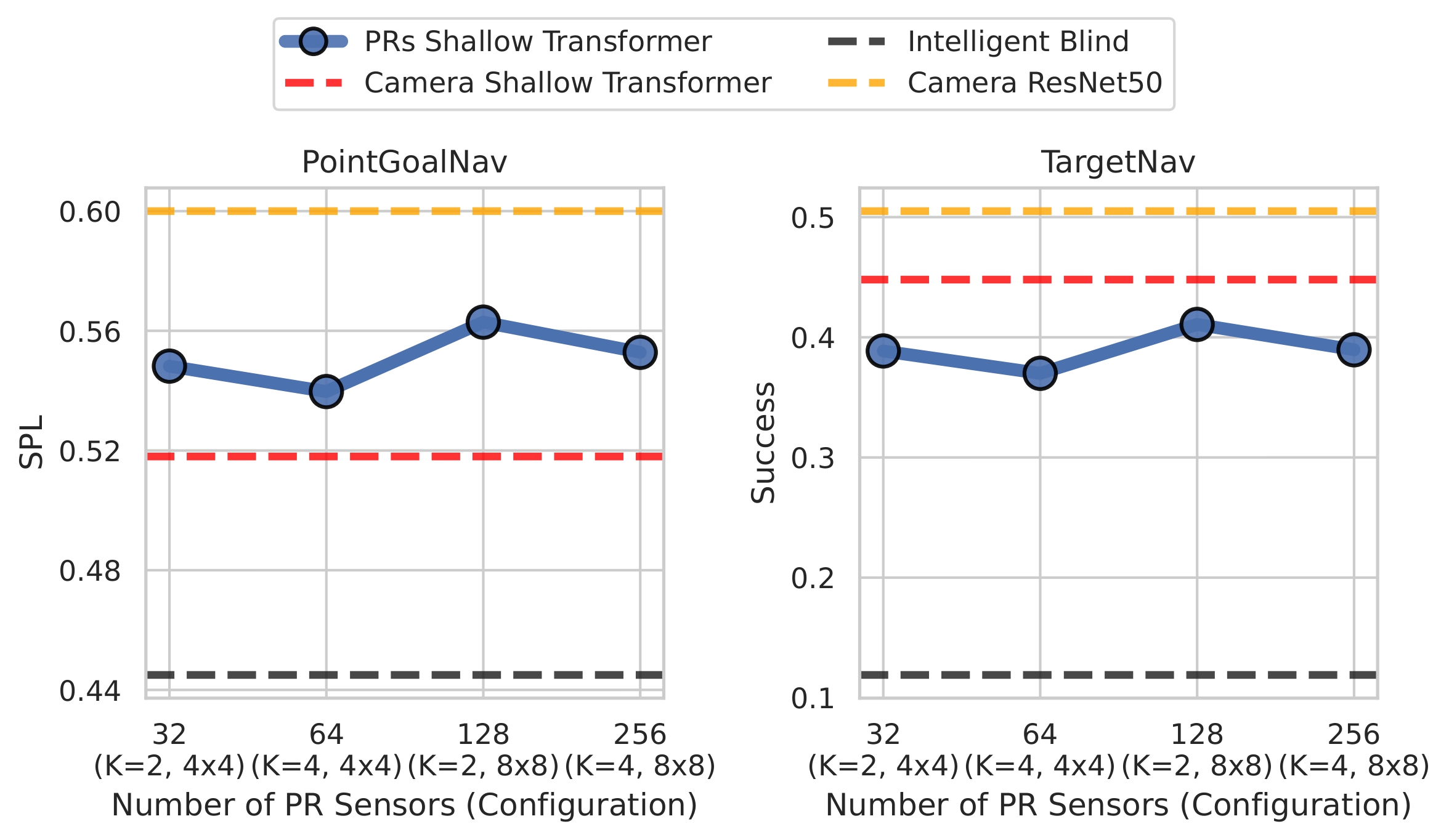
Photoreceptors are effective visual sensors for navigation tasks. Even with a handful of photoreceptors, PR agents significantly outperform blind agents and achieve performance closer to or better than that of the camera agent with the same shallow encoder (getting close to the gold standard.)
Continuous Control in DMC
DeepMind Control (DMC) suite provides a variety of continuous control tasks, including reaching, manipulation, locomotion, etc. We consider use the following six tasks: Reacher: Hard, Walker: Stand, Walker: Walk, Walker: Run, Finger: Spin, and Finger: Turn Easy.
In these tasks, visual information from photoreceptors is used to sense the agent's state, a role that can also be fulfilled by a camera or nonvisual joint sensors. In our experiments, however, the agents rely solely on visual information.
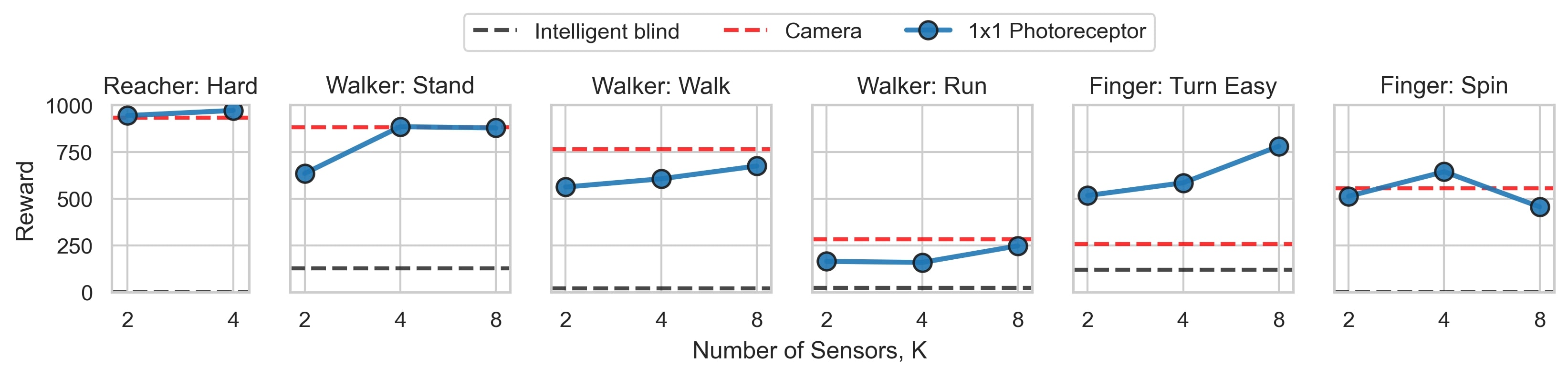
Simple photoreceptor sensors lead to high performance similar to the camera sensor in most tasks from the DeepMind Control suite. In most tasks, we find that just a few PRs significantly outperform the blind agent and perform on par with the high-resolution camera sensor.
Examplar episode of a PR agent in the Walker: Walk task. Left Image: vizualization of the the used computational design. Video: "PR, RGB" shows the observed RGB values from each photoreceptor. "Luminence" shows the same PR observations but reduces them to luminence values for visualization purpose (the color of each line corresponds to the PR color in the design vizualization on the left). "Reward" shows the reward at each step. "Side View" visualizes the agent at each step. (Note that this agent was trained for x3 more steps, hence, its superior performance compared to the results above). For related work on bipedal locomotion, see the Monty Python's Ministry of Silly Walks.
Simple low-resolution sensors in the real-world
To evaluate generalization and ensure that the strong performance of photoreceptors is not confined to simulators, we conducted the target navigation experiment (without access to GPS+Compass sensor) in a real-world setting.
We deployed a control policy using 64 PRs (less than 1% of the camera resolution) on a real robot. It demonstrates impressive performance, successfully navigating to the target ball in an unknown room with no real-world training, relying solely on the low-resolution visual signal.
An robot equipped only with 64 PRs navigates to the target ball in a room.
The Design of Simple Visual Sensors
Design is essential for the effectiveness of photoreceptor sensors
The design of a photoreceptor sensor (or a B x B grid), is varies by changing the extrinsic (position and orientation) and intrinsic (field of view) parameters. The position of a sensor is defined by a 3-dimensional vector in space, constrained to be on the agent's body. The orientation of a sensor is defined by its pitch, yaw and roll, while the field of view can be between 0 and 180 degrees. Therefore, each sensor has an associated 7-dimensional design parameter vector θi = (xi, yi, zi, pitchi, yawi, rolli, fovi).
The design of photoreceptors plays a crucial role in achieving good performance. The performance of an agent with a poor design can drop drastically compared to the best design for the corresponding task as seen below. For each setting (task and number of sensors), the variance in performance of different designs is large.
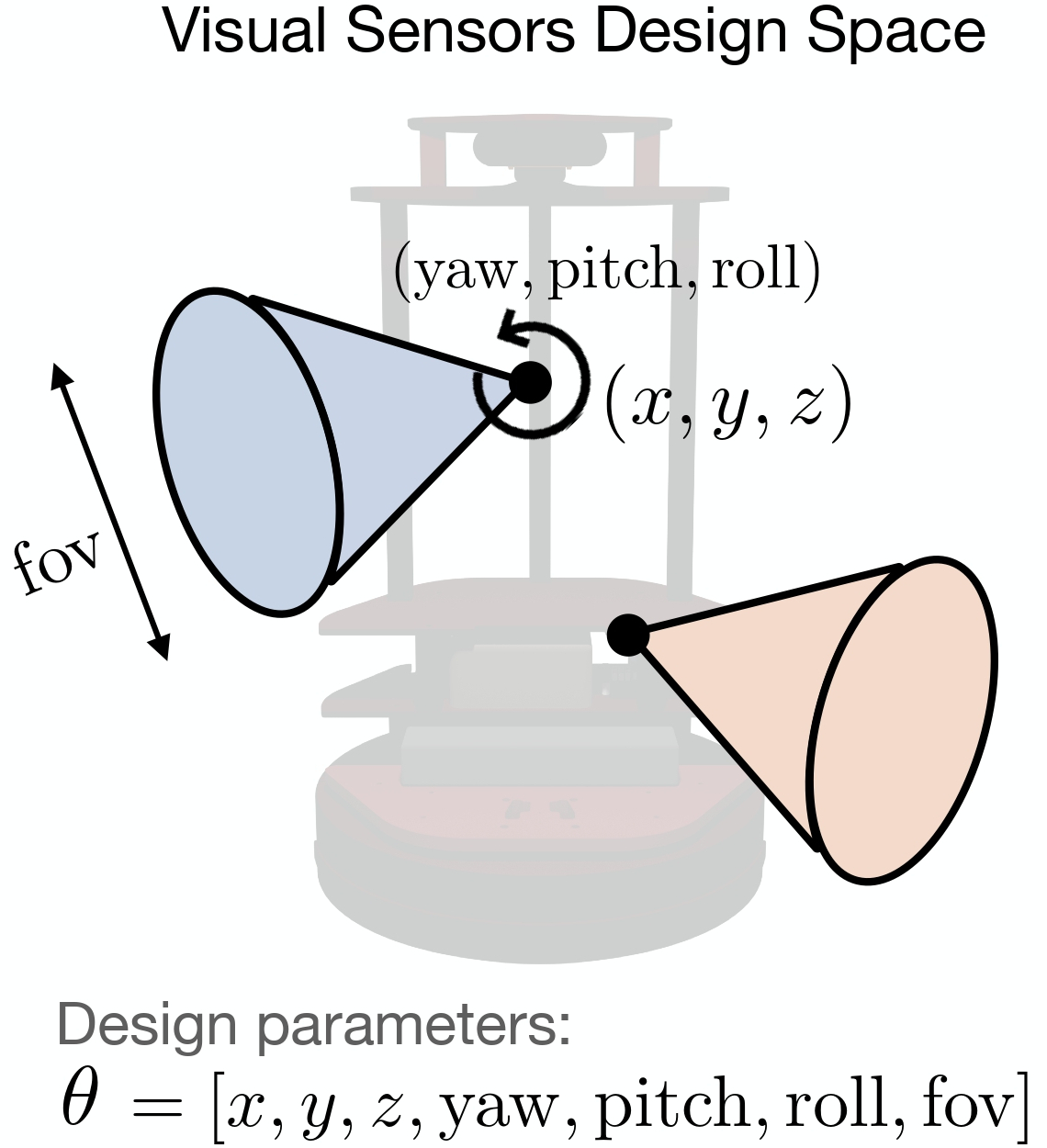
Design space of PRs.
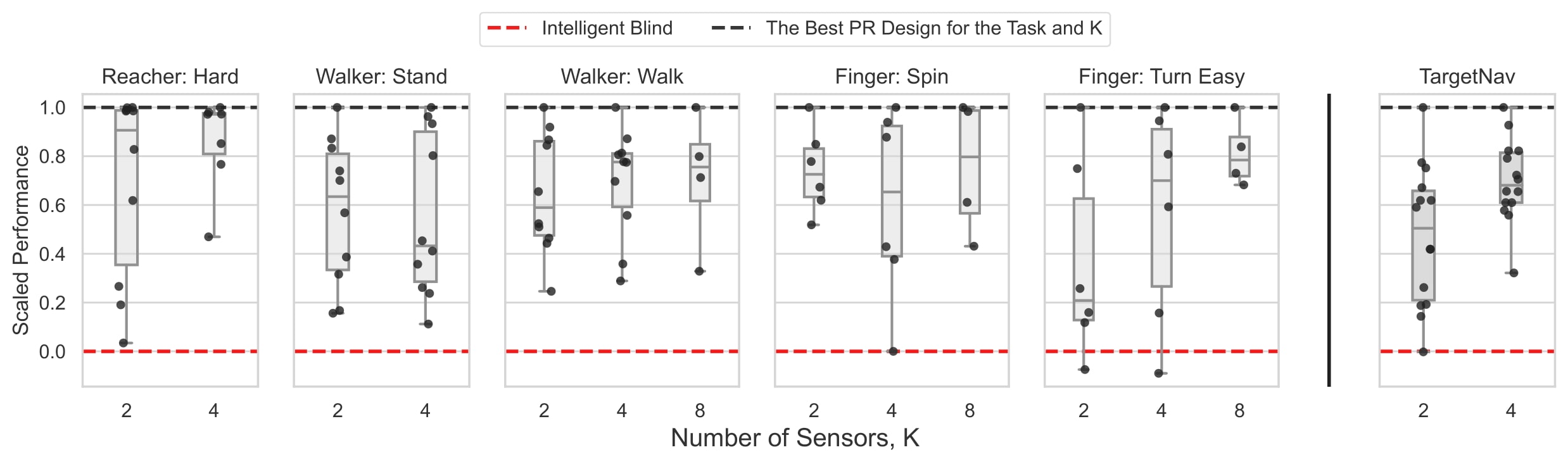
Well-designed PRs are important to achieve good performance; poorly-designed photoreceptor sensors lead to a significant drop in performance.
Computational Design Optimization
To find a well-performing design automatically, we develop a computational design optimization method, which tailors designs to the specific agent's morphology, environment, and task. A naive approach would be to use a black-box optimization method by training a design-specific control policy for each new design proposal and selecting the best one. This approach is prohibitively expensive as training a control policy for each new design is costly. Instead, we cast the problem as a joint optimization of the design and control policies. To have a control policy that can adapt to different designs, we train a design-conditional "generalist" policy that is trained to implement control for any given design. This results in a efficient optimization method which allows us to find well-performing designs leading to a close-to-camera performance in most cases.
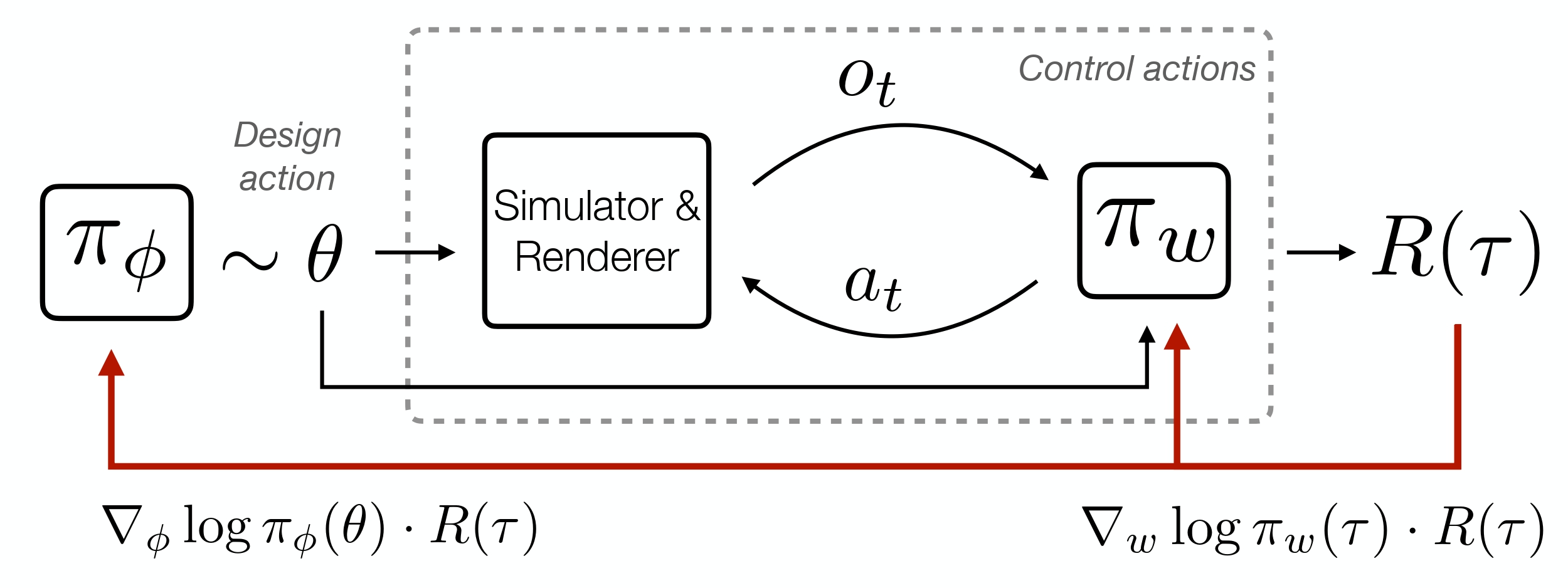
Computational design via joint optimization. We develop a computational design optimization method that jointly trains a control policy πw and a design policy πφ. Instead of training design-specific control policies for each design, we train a design-conditional policy that implements control for a given design.
Design optimization trajectory visualization. The design optimization method improves on the intial random design producing a significantly better computational performing design. We visualize the trajectory of the design updates as it changed by the proposed joint optimization method.
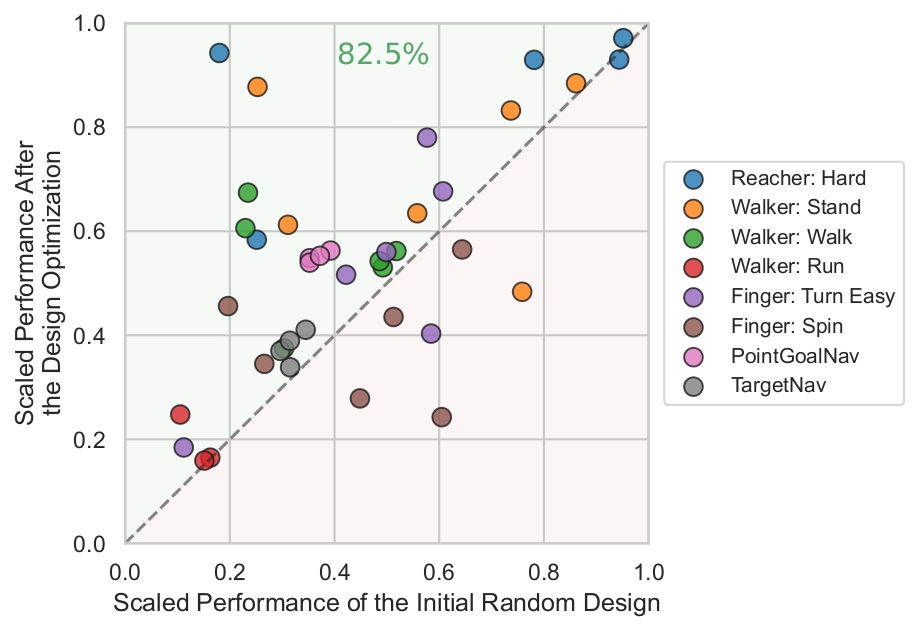
Design optimization improves upon the initial random designs. The green and red regions signify success and failure cases, respectively. We find that the proposed optimization method successfully improves the performance of the initial random design in most cases (82.5% of points are in the green region).
The design optimization method enhances the performance of a camera agent as well by finding a more effective design than intutive design in both navigation tasks. In PointGoalNav, computational design improves the efficiency metric SPL from 0.447 to 0.518. In TargetNav, it boosts the success rate from 0.363 to 0.405.
Comparison to intuitive designs
Since there is no single obvious way to design simple visual sensors, we conducted a human survey to collect photoreceptor designs based on intuition.
We ask participants to design the design parameters of visual sensors in our defined design space. We ask participants to find the photoreceptors' design parameters for a given task and agent morphology. We collect eight designs for the TargetNav visual navigation task and six designs for the Walker agent in DMC and evaluate them on Walk and Stand tasks.
We find that the best human intuition can provide well-performing designs, and computational design is among the best designs (or the best one) in most cases. We also find a high variance in the performance of different intuitive designs in all settings, signifying the importance of a computational approach to visual design.
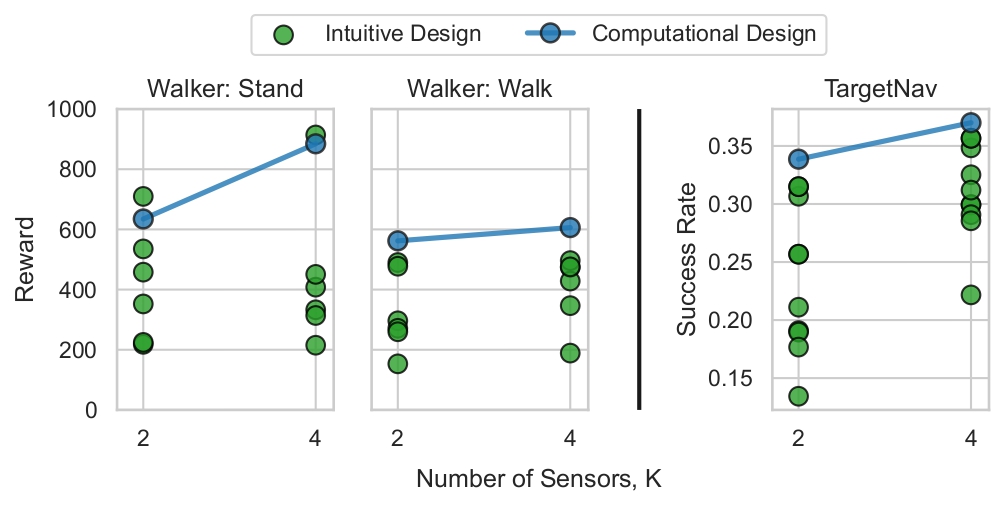
Comparison of computational and human intuitive designs. We compare intuitive designs collected via survey with the best computational design found via design optimization. The computational design is among the best designs in all settings
While human design is effective in anthropomorphic and intuitive domains, such as placing a camera on a robot, many design areas are not native to humans. Examples include distributed low-resolution eyes and environments unlike typical living spaces, such as medical imaging. These scenarios highlight the need for a computational design framework to overcome anthropomorphic biases.